Overview
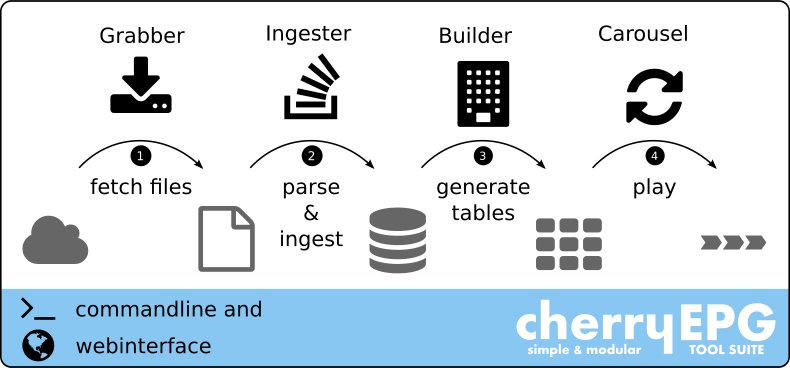
EPG workflow
The job of generating a suitable EIT stream, the EPG workflow, can be divided into individual tasks. Each of these tasks is performed by a separate module:
Grabber
The first process in the EPG workflow is to get the service schedule data. Typically, the content provider should provide this information, but in practice there are other sources. There are usually companies that obtain this information from various sources and then sell it to network operators.
Ingester
Once the schedule data files for each service are retrieved, the files must be processed to extract the desired event data. This information is stored in a database for later use. This process is called ingesting. Because there are different file formats to describe event data, cherryEPG has a number of different parsers that can read these files and extract the information.
Builder
The builder processes the schedule data in the database at regular intervals and generates the desired Event Information Tables.
Carousel
Finally, the prepared EIT must be played in an endless loop. Therefore, this is often referred to as a carousel. Whenever there is an update in the EIT, the carousel must replace the currently played tables with new ones. This exchange should appear invisible or seamless to the multiplexer.
Command-line interface
The control and administration of the EPG workflow takes place via the Linux shell. A command line tool is used to control the modules.
Web interface
A picture is worth a thousand words, and it’s often easier to click symbols than to write cryptic words on the command line. For this purpose cherryEPG includes a web interface which offers the user an overview of the system. It is also possible to do simple tasks.